

HOME  論文/ハイライト 研究ハイライト 論文ハイライト G-Links:生物学のビッグデータの「収集・統合・抽出」を支援する新システム
論文/ハイライト 研究ハイライト 論文ハイライト G-Links:生物学のビッグデータの「収集・統合・抽出」を支援する新システム
16.06.07
G-Links:生物学のビッグデータの「収集・統合・抽出」を支援する新システム
(16.06.07)
分散して存在するさまざまな生物学情報を、より効率よく利用することが可能に
Oshita K, Tomita M and Arakawa K. (2015) G-Links: a gene-centric link acquisition service [version 2; referees: 2 approved]. F1000Research 2015 3:285
いわゆる次世代シーケンサに代表されるような網羅的測定・解析技術や機器の飛躍的な向上により、生物学者が得ることのできるデータ量や、その種類は著しく増加している。これらのデータやその解析ツールの多くは、数千個にもおよぶ生物学データベースや解析WebサービスとしてWeb上でオープンに公開されている。その結果、多くのデータベースから多岐にわたる生物学情報をもちいて、複雑な生命システムの理解に向けた研究に取り組むことが可能になってきている。一方で、実際に生物学研究を進めていく上では大量の分散する生物学データを集め、フォーマットを変換し、異なるIDを名寄せしながら統合し、その上で必要な情報を抽出する作業が発生する。バイオインフォマティクス研究ではこのようなデータの前処理にその労力の大半が費やされてしまっているのが現状である。この問題を解決するために慶應義塾大学大学院・政策・メディア研究科修士課程(当時)の大下和希氏らは、新システムG-Linksを開発した。これは多数の生物学Webリソースを効率的に統合し、そこからユーザが必要とする生物学データセットを高速かつ自動的に抽出するシステムだ。
全データベースを単純に統合したデータベースを作成・利用することは、その運用コストや計算資源の問題から非常に難しい。これに対し、G-Linksでは多くの生物学データベースがLinked Data構造を取っているという点から解決をおこなった。Linked Dataモデルとは、各データベースがオンラインかつ公的に提供されており、それぞれのエントリー間が他データベースのエントリとLinkで繋がることでデータベース間の関係性を表現するモデルである。インターネット上のウェブページがそれぞれHyperLinkで繋がっているように、データベースの個別のデータエントリがさまざまなデータベースと繋がっている状態である。よって、多くの生物学データベースがこの構造をとっていることを利用すれば、「複数の生物学データベースの統合問題」を「Linked Dataネットワーク上での単純な経路探索問題」に置き換えることが可能になるのである。さらに、G-Linksでは生物情報を高速かつ網羅的に統合・収集するために、 このLinked Dataネットワークの生物学情報が遺伝子情報をベースとして整理されている。 これは、"全ての遺伝情報は遺伝子から伝播する"というセントラルドグマの考えにもとづいている。遺伝子情報を中心に整理されたLinked Dataネットワークをたどるという一連の工夫によって、G-Linksではユーザが対象とする生物学情報のみを、高速かつ網羅的に取得・統合することが可能になっている。
さらに、G-Linksでは収集した生物学情報から必要な情報だけを抽出して取得するフィルタリング機能を提供されており、「データ取得・統合・抽出」の全行程を高速・自動的に行うことが可能となっている。その他にも、G-Linksでは、配列類似性検索によるIDマッピングを用いた配列ベースでの情報取得や、多数の出力データ形式サポートもおこなうことによって、ユーザの利便性向上や様々な分析ツールとの連携を可能にしている。また、生物分析Webサービスの結果を合わせて提供することで、分析サービスの結果とデータベースを同じ生物情報として統合して扱うことが可能になっている。今後もこのような周辺技術との連携を強めることで、バイオインフォマティクス研究の汎用的なベースシステムとしての活用が期待できる。
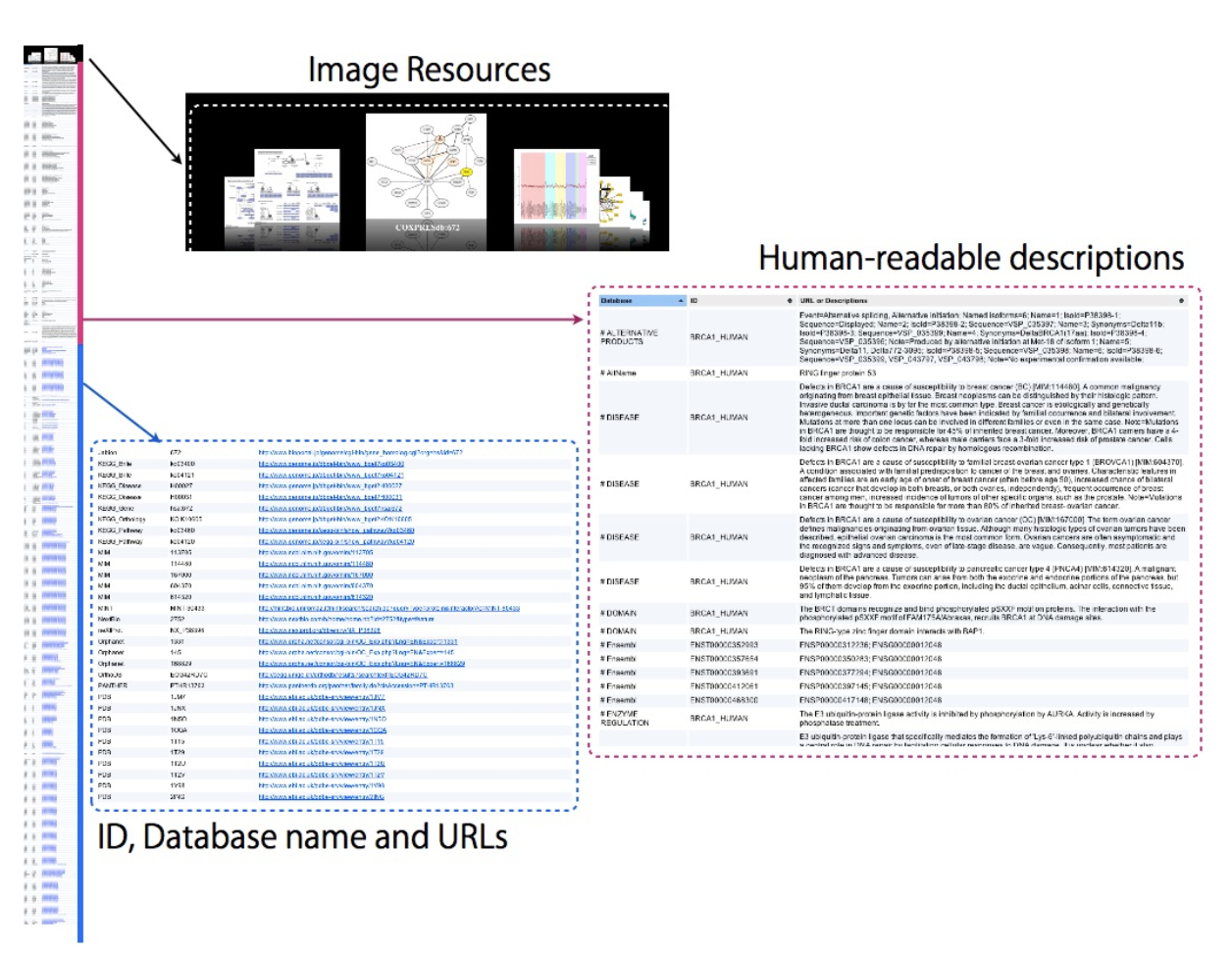
図:G-Linksを利用し、乳がん原因遺伝子の一つであるBRCA1遺伝子についての情報を取得した際の例
左側に、Webブラウザでhttp://link.g-language.org/BRCA1_HUMANへアクセスして情報を取得した場合の全結果を、右側にそれぞれのセクションで得られる情報の一部を示している。G-Linksをもちいることで、本来個別のデータベースに存在する変異・発現・タンパク間相互作用・パスウェイなどのさまざまな種類生物学情報を高速かつ容易に取得することが可能となる。ブラウザからアクセスした場合は、画像情報や人が読むための記述情報が画面上部に表示される。そのため、まずユーザが知りたい遺伝子に関する概要を容易に把握することができ、次により詳細な情報を取得したい場合は下部のURLをたどるだけで可能となる。
(詳細なドキュメントについても http://link.g-language.org/ に記載)
[編集:川本 夏鈴]